Monday, October 28th, 2013
If you’re trying to connect to the Virtual KVM (console) on a HP Lights-Out 100i (LO100i) using the Remote Console Client Java applet, you might be getting an error in the order of
Username / Password invalid
Or:
com.serverengines.r.rdr.EndOfStream: EndOfStream
This is a known problem with firmware version 4.24 (or Earlier):
The Virtual Keyboard/Video/Mouse (KVM )will not be accessible
on HP ProLiant 100-series servers with Lights-Out 100 Base
Management Card Firmware Version 4.24 (or earlier), if the server
has been running without interruption for 248 days (or more). When
this occurs, when attempting to access Virtual KVM/Media as shown
below, the browser will generate the following message[...]
As a solution, HP recommends:
As a workaround, shut down the server and unplug the power cable.
After a few seconds, reconnect the power cable and restart the server.
I’ve found that it isn’t required to actually unplug the powercable. For me, remotely cold-restarting the iLoM card got rid of the problem. You can remotely cold-start the iLoM with ipmitool:
$ ipmitool -H <ILOM_IP> -U <USERNAME> mc
Password:
MC Commands:
reset <warm|cold>
guid
info
watchdog <get|reset|off>
selftest
$ ipmitool -H <ILOM_IP> -U <USERNAME> mc reset cold
Password:
Sent cold reset command to MC
Now we wait until the iLoM comes back up and we can succefully connect to the console via the KVM Java applet.
Friday, September 27th, 2013
I’m trying out Juju with the ‘local’ environment, and ran into the following error:
$ sudo juju bootstrap
error: error parsing environment "local": no public ssh keys found
The Getting Started Guide mentions nothing of this error, and I couldn’t find a solution on the web. After a bit of reading, it seems Juju requires a passwordless SSH key be available in your ~/.ssh dir. So to get rid of this error, just generate a new key with no password:
$ ssh-keygen
Generating public/private rsa key pair.
Enter file in which to save the key (/home/fboender/.ssh/id_rsa):
Enter passphrase (empty for no passphrase): <EMPTY>
Enter same passphrase again: <EMPTY>
Now you bootstrap Juju:
$ sudo juju bootstrap -e local
$
Monday, September 16th, 2013
HAR, HTTP Archive, is a JSON-encoded dump of a list of requests and their associated headers, bodies, etc. Here’s a partial example containing a single request:
{
"startedDateTime": "2013-09-16T18:02:04.741Z",
"time": 51,
"request": {
"method": "GET",
"url": "http://electricmonk.nl/",
"httpVersion": "HTTP/1.1",
"headers": [],
"queryString": [],
"cookies": [],
"headersSize": 38,
"bodySize": 0
},
"response": {
"status": 301,
"statusText": "Moved Permanently",
"httpVersion": "HTTP/1.1",
"headers": [],
"cookies": [],
"content": {
"size": 0,
"mimeType": "text/html"
},
"redirectURL": "",
"headersSize": 32,
"bodySize": 0
},
"cache": {},
"timings": {
"blocked": 0,
}
},
HAR files can be exported from Chrome’s Network analyser developer tool (ctrl-shift-i → Network tab → capture some requests → Right-click and select Save as HAR with contents. (Additional tip: Check the “Preserve Log on Navigation option – which looks like a recording button – to capture multi-level redirects and such)
As human-readable JSON is, it’s still difficult to get a good overview of the requests. So I wrote a quick Python script that turns the JSON into something that’s a little easier on our poor sysadmin’s eyes:
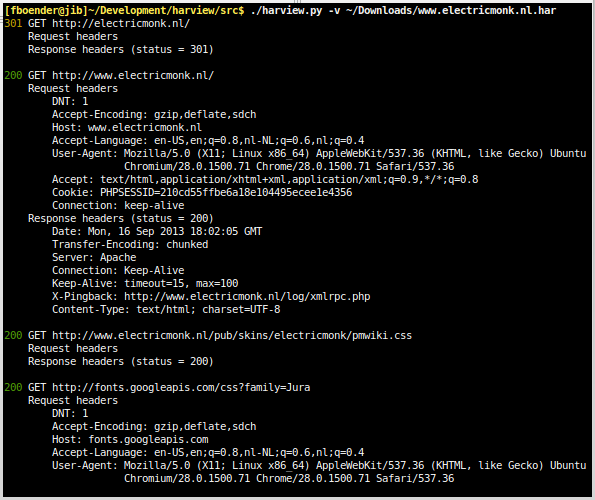
It supports colored output, dumping request headers and response headers and the body of POSTs and responses (although this will be very slow). You can filter out uninteresting requests such as images or CSS/JSS with the --filter-X options.
You can get it by cloning the Git repository from the Bitbucket repository.
Cheers!
Thursday, August 29th, 2013
It seems even professional sysadmins occasionally forgets the bare minimum configuration that should be done on a new machine. As a developer and part-time system administrator, I can’t count the number of times I’ve had to waste significantly more time Here’s a, by no means exhaustive, list of things you should configure on any new machine you deploy.
1. Pick a good hostname
Set a sane hostname on your machine. Something that describes what the machine is or does. Something that uniquely identifies it from any other machines on, at least, the same network. For instance, machine for a client called Megacorp might be called “mc-tst-www-1” to identify the first test WWW server for Megacorp. The primary production loadbalancer might be called “mc-prod-lb-1“. Never have your junior sysadmin bring down the master database backend because he thought he was on a different machine.
2. Put all hostnames in /etc/hosts
Put all hostnames your machine uses in the /etc/hosts file to avoid annoying DNS lookup delays and other problems.
3. Install ntpd
Running into problems related to clock drift on your server is not a matter of “if”, but a matter of “when”. And with clock drift it will be sooner rather than later, depending on which direction your clock is drifting in. Install NTPd, and synchronize it to the same servers as all your other machines. Don’t use a default pool if you can avoid it, because they might use Round Robin DNS and give you different servers. Theoretically this shouldn’t pose a problem. Theoretically…
If you’re running virtual machines, turn off Virtualbox/VMWare/whatever’s time synchronization. They’ve historically been proven to be very unreliable[1]. Install ntpd anyway. And I swear, as a developer, I will kick you in the face if I ever have to diagnose another problem caused by a lack of ntpd.
4. Make sure email can be delivered
This one is simple. Make sure email can be delivered to the outside world. Many programs and scripts will need to be able to send email. Make sure they can. Ideally, you should have a dedicated SMTP server set up on your network that hosts can relay email through. A gateway firewall should prevent all other outgoing traffic for port 25, unless you want your server to be turned into a zombified spam node (which will happen).
5. Cron email
Configure Cron such that output is emailed to an actual person. You want to know about that “No space left on device” error that crashed your cobbled-together backups script. You can specify the email address with the MAILTO directive in the crontab file. Don’t forget about user crontabs! Since it’s hard to ensure every user crontab has a MAILTO setting, you may want to configure your SMTP server to automatically forward all email to a special email address.
6. Protect the SSH port
Unauthorized probing of the SSH port will happen, unless you prevent it. Weak passwords can be easily guessed in a few hundred tries. Timing attacks can be used to guess which accounts live on the system, even if the attacker can’t guess the password. There are several options for securing your SSH port
- Listen on a different port. This is the least secure option, as it can usually be easily probed using a port scanner. It will fool some of the botnets out in the wild blindly scanning on port 22, but it won’t keep out the more advanced attackers. If you go for this option, don’t go for port 2222, but pick something arbitrary high, such as 58245.
- Install Fail2ban. It scans your logs and blocks any IPs that show malicious signs. This is a good idea, regardless of whether you want to secure SSH or not
- Firewall off the port completely. Only open access from a few select IPs, such as your management network. Use a port knocker to open SSH ports on demand in case you absolutely need access from unpredictable IPs.
7. Configure a firewall
This should go without saying.. install and configure a firewall. Firewall everything. Incoming traffic, outgoing traffic, all of it. Only open up what you need to open. Don’t rely on your gateway’s firewall to do its job; you will regret it when other machines on your network get compromised.
8. Monitor your system
Monitor your system, even if it’s just a simple shell script that emails you about problems. Disks will fill up, services will mysteriously shut down and your CPU load will go to 300. I highly recommend also monitoring important services from a remote location.
9. Configure resource usage
Running Apache, a database or some Java stack? Configure it properly so it utilizes the resources your system has, but doesn’t overload it. Configure the minimum and maximum connections Apache will accept, tune the memory your database is allowed to use, etc.
10. Keep your software up-to-date
Install something like apt-dater to keep your software up-to-date. Many server compromises are directly linked to outdated software. Don’t trust yourself to keep a machine up to date. You will forget. If you’re running third-party software not installed from your package repository, subscribe to their security announcement mailing list and keep a list of all third-party software installed on every server. A tool such as Puppet, Chef or Ansible can help keep your system not only up to date, but uniform.
11. Log rotation
Make sure all logs are automatically rotated, or your disks will fill up. Take a look at /etc/logrotate.d/ to see how. For instance, for Apache vhosts that each have their own log directory, you can add an entry such as:
/var/www/*/logs/*.log {
weekly
missingok
rotate 52
compress
delaycompress
notifempty
# create 640 root adm # Disabled so old logfile's properties are used.
sharedscripts
postrotate
if [ -f /var/run/apache2.pid ]; then
/etc/init.d/apache2 restart > /dev/null
fi
endscript
}
12. Prevent users from adding SSH keys
Remove the ability for users to add new authorized keys to their account. Which keys are allowed to connect should be in the admin’s hand, not the users. Having the Authorized Keys files scattered all over your system also makes maintenance harder. To do this, change the AuthorizedKeysFile setting in /etc/ssh/sshd_config:
#AuthorizedKeysFile %h/.ssh/authorized_keys
AuthorizedKeysFile /etc/ssh/authorized_keys/%u
13. Limit user crontabs
Limit which users can create personal crontab entries by placing only allowed usernames in /etc/cron.allow. This prevents users from creating CPU/IO heavy cronjobs that interfere with your nightly backups.
14. Backups, backups and more backups
Make backups! Keep local backups for easy restoring of corrupt files, databases and other disasters. Databases should be backed up locally each night, if at all possible. Rotate backups on a daily, weekly and monthly cycle. Keep off-site backups too. For small servers I can highly recommend Boxbackup. It keeps remote encrypted backups, does full and incremental backups, keeps a history and does snapshotting as well as continues syncing. Only delta’s (changes in files) are transferred and stored, so it is light on resources. wrote an article on setting it up which might prove useful.
15. Install basic tools
Make sure basic tools for daily admin tasks are pre-installed. There’s nothing more annoying than having to track down problems and not having the means to do so, especially when your network refuses to come up. Some essential tools:
- vi
- iotop
- strace
- Whatever more you need..
16. Install fail2ban
I’ve already mentioned this in the “Protect your SSH port”, but it bears mentioning again: install Fail2ban to automatically block offending IPs.
Conclusion
That’s it. These are the things I would consider the bare minimum that should be properly configured when you deploy a new machine. It will take a little bit more time up front to configure machines properly, but it will save you time in the end. I can highly recommend using Puppet, Chef or Ansible to help you automate these tasks.
Notes
[1]This was the case a few years ago. I’m not sure it still is for VMWare. For VirtualBox, it most certainly is, but you wouldn’t run that in a production environment probably. At the very least, install NTPd on your host.
Monday, April 15th, 2013
 I wrote a small tool that assists in creating mirrors of your public and private Bitbucket Git repositories and wikis. It also synchronizes already existing mirrors. Initial mirror setup requires that you manually enter your username/password. Subsequent synchronization of mirrors is done using Deployment Keys.
I wrote a small tool that assists in creating mirrors of your public and private Bitbucket Git repositories and wikis. It also synchronizes already existing mirrors. Initial mirror setup requires that you manually enter your username/password. Subsequent synchronization of mirrors is done using Deployment Keys.
You can download a tar.gz, a Debian/Ubuntu package or clone it from the Bitbucket page.
-
Clone / mirror / backup public and private repositories and wikis.
-
No need to store your username and password to update clones.
-
Exclude repositories.
-
No need to run an SSH agent. Uses passwordless private Deployment Keys. (thus without write access to your repositories)
Usage
Here's how it works in short. Generate a passwordless SSH key:
$ ssh-keygen
Generating public/private rsa key pair.
Enter file in which to save the key: /home/fboender/.ssh/bbcloner_rsa<ENTER>
Enter passphrase (empty for no passphrase):<ENTER>
Enter same passphrase again: <ENTER>
You should add the generated public key to your repositories as a Deployment Key. The first time you use bbcloner, or whenever you've added new public or private repositories, you have to specify your username/password. BBcloner will retrieve a list of your repositories and create mirrors for any new repositories not yet mirrored:
$ bbcloner -n -u fboender /home/fboender/gitclones/
Password:
Cloning new repositories
Cloning project_a
Cloning project_a wiki
Cloning project_b
Now you can update the mirrors without using a username/password:
$ bbcloner /home/fboender/gitclones/
Updating existing mirrors
Updating /home/fboender/gitclones/project_a.git
Updating /home/fboender/gitclones/project_a-wiki.git
Updating /home/fboender/gitclones/project_b.git
You can run the above from a cronjob. Specify the -s argument to prevent bbcloner from showing normal output.
The mirrors are full remote git repositories, which means you can clone them:
$ git clone /home/fboender/gitclones/project_a.git/
Cloning into project_a...
done.
Don't push changes to it, or the mirror won't be able to sync. Instead, point the remote origin to your Bitbucket repository:
$ git remote rm origin
$ git remote add origin git@bitbucket.org:fboender/project_a.git
$ git push
remote: bb/acl: fboender is allowed. accepted payload.
Get it
Here are ways of getting bbcloner:
More information
Fore more information, please see the Bitbucket repository.
Sunday, March 10th, 2013
Every now and then I have to work on something that involves LDAP, and every time I seem to have completely forgotten how it works. So I’m putting this here for future me: a quick introduction to LDAP basics. Remember, future me (and anyone else reading this), at the time of writing you are by no means an LDAP expert, so take that into consideration! Also, this will be very terse. There are enough books on LDAP on the internet. I don’t think we need another.
What is LDAP?
- LDAP stands for Lightweight Directory Access Protocol.
- It is a standard for storing and accessing “Directory” information. Directory as in the yellow pages, not the filesystem kind.
- OpenLDAP (unix) and Active Directory (Microsoft) implement LDAP.
- Commonly used to store organisational information such as employee information.
- Queried for access control definitions (logging in, checking access), addressbook information, etcetera.
How is information stored?
- LDAP is a hierachical (tree-based) database.
- Information is stored as key-value pairs.
- The tree structure is basically free-form. Every organisation can choose how to arrange the tree for themselves, although there are some commonly used patterns.
The tree
An example of an LDAP tree structure (some otherwise required attributes are left out for clarity!):
dc=com
dc=megacorp
ou=people
uid=jjohnson
objectClass=inetOrgPerson,posixAccount
cn=John Johnson
uid=jjohnson
mail=j.johnson@megacorp.com
uid=ppeterson
objectClass=inetOrgPerson,posixAccount
cn=Peter Peterson
uid=ppeterson
mail=p.peterson@megacorp.com
- Each leaf in the tree has a specific unique path called the Distinguished Name (DN). For example: uid=ppeterson,ou=people,dc=megacorp,dc=com
- Unlike file paths and most other tree-based paths which have their roots on the left, the Distinguished Name has the root of the tree on the right.
- Instead of the conventional path separators such as the dot ( . ) or forward-slash ( / ), the DN uses the comma ( , ) to separate path elements.
- Unlike conventional paths (e.g. /com/megacorp/people/ppeterson), the DN path includes an attribute type for each element in the path. For instance: dc=, ou= and uid=. These are abbreviations that specify the type of the attribute. More on attribute types in the Entry chapter.
- It is common to arrange the tree in a globally unique way, using dc=com,dc=megacorp to specify the organisation.
- Entries are parts of the tree that actually store information. In this case: uid=jjohnson and uid=ppeterson.
Entries
An example entry for DN uid=jjohnson,ou=people,dc=megacorp,dc=com (some otherwise required attributes are left out for clarity!):
objectClass=inetOrgPerson,posixAccount
cn=John Johnson
uid=jjohnson
mail=j.johnson@megacorp.com
- An entry has an Relative Distinguished Name (RDN). The RDN is a unique identifier for the entry in that part of the tree. For the entry with Distinguished Name (DN) uid=jjohnson,ou=people,dc=megacorp,dc=com, the RDN is uid=jjohnson.
- An entry stores key/value pairs. In LDAP lingo, these are called attribute types and attribute values. Attribute types are sometimes abbreviations. In this case, the attribute types are cn= (CommonName), uid= (UserID) and mail=.
- Keys may appear multiple times, in which case the are considered as a list of values.
- An entry has one or more objectClasses.
- Object classes are defined by schemas, and they determine which attributes must and may appear in an entry. For instance, the posixAccount object class is defined in the nis.schema and must include cn, uid, etc.
- Different object classes may define the same attribute types.
- A reference of common object classes can be found in Appendix E of the excellent Zytrax LDAP Guide.
- A reference of common attribute types can also be found in Appendix E.
Connecting and searching LDAP servers
The most common action to perform on LDAP servers is to search for information in the directory. For instance, you may want to search for a username to verify if they entered their password correctly, or you may want to search for Common Names (CNs) to auto-complete names and email addresses in your email client. In order to search an LDAP server, we must perform the following:
- Connect to the LDAP server
- Authenticate against the LDAP server so we are allowed to search. This is called binding. Basically it’s just logging in. We bind against an LDAP server by specifying a user’s DN and password. This can be confusing because there can be DNs/password with which you can bind in the LDAP, but also user/passwords which are merely stored so that other systems can authenticate users using the LDAP server.
- Specify which sub-part of the tree we wish to search. This is called the Base DN (Base Distinguished Name). For example: ou=people,dc=megacorp,dc=com, so search only people. Different bind DN’s may search different parts of the tree.
- Specify how deep we want to search in the tree. This is called the level. The level can be: BaseObject (search just the named entry, typically used to read one entry), singleLevel (entries immediately below the base DN), orwholeSubtree (the entire subtree starting at the base DN).
- Specify what kind of entries we’d like to search for. This is called the filter. For example, (objectClass=*) will search for ANY kind of object class. (objectClass=posixAccount) will only search for entries of the posixAccount object class.
Here’s an example of connecting, binding and searching an LDAP server using the ldapsearch commandline util:
$ ldapsearch -W -h ldap.megacorp.com -D "uid=ldapreader,dc=megacorp,dc=com"
-b ou=people,dc=megacorp,dc=com "(objectclass=*)"
password: ********
- -W tells ldapsearch to prompt for a password.
- -h is the hostname of the LDAP server to connect to.
- -D is the Distguished Name (DN), a.k.a the username, with which to connect. In this case, a special ldapreader account.
- -b is the Base DN, a.k.a the subtree, we want to search.
Finally, we specify a search filter: "(objectclass=*)". This means we want to search for all object classes.
The previous example, but this time in the Python programming language:
import ldap
l = ldap.initialize('ldap://ldap.megacorp.com:389')
l.bind('uid=ldapreader,dc=megacorp,dc=com', 'Myp4ssw0rD')
l.search_s('ou=people,dc=megacorp,dc=com', ldap.SCOPE_SUBTREE,
filterstr="(objectclass=*)")
Further Reading
That’s it! Like I said, it’s terse! If you need to know more about LDAP, here are some good resources on it:
Friday, January 25th, 2013
Say you’re trying to set the “ignore” property on something in a subversion checkout like this:
svn propset svn:ignore "foo.pyc" .
Next you do a svn status:
M foo.pyc
It seems it isn’t working. In order to fix this, you must remember to first:
- Remove the file from subversion and commit
svn update all the checkouts of that repository so that the file is gone everywhere!- Set the
svn:ignore propery
- Now commit the property change, or
svn status will still show it (even in the local checkout)!
svn update all the checkouts of the repository
So:
host1$ svn rm foo.pyc && svn commit -m "Remove compiled python code"
host2$ svn update
host1$ svn propset svn:ignore "foo.pyc" .
host1$ svn commit -m "Ignore compiled python code"
host2$ svn update
If you get conflicts because you didn’t follow these steps exactly:
host2$ svn update
C foo.pyc
host2$ svn resolve --accept working foo.pyc
host2$ svn rm foo.pyc
host2$ svn update
At revision 123
That should solve it.
If you want all your subversion problems solved, try this.
Wednesday, November 21st, 2012
The Joomla v2.5 backend administrator interface by default will log you out after you’ve been inactive for 24 minutes (some on the internet claim it’s 15, others 30 minutes. For me, it seems it was 24). This is quite annoying, and usually easily fixed in most PHP applications by changing the session timeout. Joomla also requires that you modify some other parts. Here’s how I got it to work:
Summary
Summary for the lazy technical people. These are the steps to modify the session timeout:
- In php.ini, find the session.gc_maxlifetime setting, and change it.
- In Joomla Admin inteface, go to Site → Global Configuration → System and change the Session Lifetime value.
- In Joomla’s root directory, open configuration.php and change public $lifetime = '1440'; to the number of seconds.
If this wasn’t enough information for you, read the following which explains more in-depth:
Steps
Step 1: Modify php.ini
Figure out which php.ini Joomla uses by creating the following “info.php” file in your Joomla directory:
Direct your browser to the file, for instance: http://mysite.example.com/info.php. You should see the purple/blue PHP info page. Locate the “Loaded Configuration File” setting. This is which php.ini file will be used. Make sure to delete the info.php file when you’re done!
Edit the file (for me its /etc/php5/apache2/php.ini) and find the following setting:
session.gc_maxlifetime = ....
Change the setting to however many seconds you want to remain logged in without activity, before being logged out automatically. I set mine to 8 hours (28800 seconds):
session.gc_maxlifetime = 28800
Step 2: Timeout in the Joomla interface
I’m not sure this step is required, but I changed it, so you may also have too.
Open the Joomla Adminisatror backend (http://mysite.example.com/administator/), login as a Super User (‘admin’ usually), and open Site → Global Configuration → System. On the right side, change Session Lifetime to the number of seconds you want to keep the session alive. For me, that’s 28000 seconds again.
Step 3: Joomla’s configuration.php
Final step. In the Joomla top directory, you’ll find a file called configuration.php. Open this file with your editor, and search for:
public $lifetime = '1440';
Change the number (1440) to the number of seconds you want the session to stay alive:
public $lifetime = '288000';
Save the file.
Step 4: Restart your webserver
As a final step, you may have to restart your webserver. How to do this depends on your installation.
Now your session should remain alive for the number of seconds specified, even if you’re not active.
Wednesday, November 14th, 2012
Why are there so many programmers who don’t know what state is, much less the impact it has on programming? Recently I was having a discussion online and some programmers kept misinterpreting everything being said by me and other programmers because they had no or little grasp of the concept of state. This is not the first time I’ve noticed that, for such an important concept, there are a surprising number of programmers who don’t understand the concept and implications of state.
The meaning of state
From Wikipedia:
the state of a digital logic circuit or computer program is a technical term for all the stored information, at a given point in time, which the circuit or program has access to. The output of a digital circuit or computer program at any time is completely determined by its current inputs and its state.
Just to be clear, “all the stored information” includes the instruction pointer, CPU registers/caches and so forth. So if at any given point in time your program is in a while loop or conditional branch, that is also part of the state.
“The output of a digital circuit or computer program at any time is completely determined by its current inputs and its state.“… Think about that for a moment, because it is important. Everything that happens from that moment on in a computer program is determined by the current inputs and its state. That means, as long as there is no other input, the output of the program is completely predictable at any time. That’s a lot (or rather, exactly) like the pseudo-random number generator in most programming languages. If you know the seed, you can predict every random number that will be produced. Each number the pseudo-RNG returns is the result of its input and its current state.
If programs are that predictable, how come there are still so many bugs in them? Well, for one thing, programs are not that predictable at all.
On the Origin of Bugs
Look at the following example:
a = 5
b = 10
c = a + b
Tell me, how many bugs does the program have? If we assume that the syntax is correct and that each variable can hold an integer number, this program contains zero bugs. Now tell me, how many bugs does this program have?
a = int(file('in', 'r').readline())
b = 10;
c = a + b;
How many bugs? One? Three? Do you know? Because I sure don’t. Here’s a few I can come up with from the top of my head:
- The file “in” may not exist
- The file “in” may not be readable
- The file “in” may disappear between opening and reading
- The file “in” may be empty
- The file “in” may not contain something that can be cast to an integer
- The system may not be able to allocate more file handles
- The system may not be able to allocate enough memory to read a line from the file
- …
I could go on, but the point should be clear. We changed only one line in our program, and now there are who-knows how many bugs in our program. Why is that? Because in our first example, the state of the program could never be influenced from outside the program at any time, since there was no input! (Yes, the memory might get corrupt from a random flipped bit or the universe might decide to suspend the laws of physics, but again: let’s not get pedantic).
When we write a piece of code, we write that code with certain assumptions. If I write:
while (i < 10) { /* ... */ };
I'm assuming variable 'i' contains some kind of number, which at the start of the loop is smaller than 10, and which during the loop will not suddenly change into, say, an open file pointer. Now if I'm not a total idiot, and I write my code properly, that last thing will never happen. Given a piece of code, it's generally not difficult to make correct assumptions about that code. But making assumptions about input into that code (in this case the contents of variable 'i'), regardless of where it came from (interactive input, the network, the filesystem, passed in as a argument into a function, whatever) is much more difficult and dangerous.
I'm going to make a sweeping generalization: Given that "the output of a digital circuit or computer program at any time is completely determined by its current inputs and its state", and given that a program's current state is determined by its starting state and all the input, and that we can thus disregard the "and its state" part of the first statement... I'm going to claim that
All bugs in a program are a result of the input into that program.
Of course, like I said, that statement is sweeping, and therefor false. But for now, assume it's true and think about the implication of it for a moment, while I correct my previous statement.
Predictable state
Of course, not all bugs in a program are a result of input into that program. Sometimes us programmers screw up, and make mistakes. This is another source of bugs in our programs. Sometimes we're tired, and we make mistakes in the syntax of our programs. Sometimes we don't pay attention, and a certain library works differently than we thought. Such bugs are easily solved. In fact, many can be automatically detected by compilers or asserts or whatever.
Another class of bugs is the one where we make assumptions about the current state of a part of our program, and write new code in accordance with those assumptions. Those assumptions could be correct, resulting in working code, or they may be incorrect, resulting in bugs.
A coworker of mine once had to write some code for an ATM. Since ATMs are reasonably sensitive, he wasn't allowed to dynamically allocate memory. That is, he could not use malloc and was only allowed to use what memory was statically allocated by the compiler. Not allowing dynamically allocated memory gets rid of entire range of problems, all of which are directly related to unpredictable state. Buffer overflows, out-of-bounds array referencing, bugs in string copying, reading input... all those problems are greatly mitigated by not having dynamically allocated memory.
You always want the state of your program to be predictable. Input makes the state unpredictable. As soon as we get input into our program, we can only hope that that input adheres to the assumptions the code makes. The current state may be valid (though unpredictable), however we cannot make any claims about future states. Only after we have sufficiently validated and sanitized any input in such a way that it adheres to the code's assumptions can we speak about a predictable state again.
This is why unclear code is such a problem. Unclear code makes it hard to reason about code, thus hard to determine whether code might lead to unpredictable states. Basically, we want to make the assumptions of code as transparent as possible.
I hope everything I've said so far makes absolutely basic sense. I hope that at this point in the article you're thinking "Well, duh", because from what I've seen of many programmers.. they don't have a clue about the relation between input, state and bugs.
"So what?"
It is important to grasp this basic concept of state because it helps you to reason about why and when certain programming techniques are a good or bad idea.
-
Functions are a good idea because they make it easier for the programmer to reason about input and its effect on state within that function. Easier reasoning about state equals better assumptions about code, resulting in less bugs.
-
Object Oriented Programming is a good idea because it groups together data and the logic that operates on that data, and therefor it allows the programmer to encapsulates state in such a way that it is harder to disrupt that state with outside influences.
-
Using global variables is a bad idea because it screws up all the assumptions code makes about that global variable. Wherever you use a global variable, you cannot reason about the state of your program, since the value of the global variable can change at any time.
-
Allowing publicly settable properties in objects (that includes setter methods, for you Java developers out there) is a bad idea because now any assumptions methods in that object make about the state of those properties can be invalid. Conversely, making the constructor the only part of the object that is allowed to have input is a good idea (even if it's not always practical)
-
goto is considered evil because it makes allows for random changing of the state of a program, and therefor can make it incredibly hard for developers to reason about the current state of the program at any point.
-
functional programming is a good idea because it avoids mutable data as much as possible, and therefor it is hard to bring the program into an undefined state.
-
Multi-threaded programs where threads write to the same memory are a bad idea because writes are non-deterministic which cause unpredictable state. This can be avoided using locking, which in itself is incredibly hard to do properly, leading to state which is difficult to reason about.
-
Smaller functions are a good idea because, again, it makes it easier to reason about the state and the changes in that state within the function.
-
...
I could go on, but I hope you get the point. Please note that these point have to be considered in context. Don't take these as absolutes, because that would go entirely against what I'm trying to say. Goto can most certainly be used to create state that is more predictable and easier to reason about. In general however, it is considered detrimental to predictable state.
Back to input
Lets jump back to input for a moment. The age-old adage goes: "Validate your input!" What does that mean? Quick question.. Given this function:
def foo(a, b):
c = a / b
return c
How many bugs are in that function? We can immediately spot a potential division by zero bug and an overflow bug. There are others, but the point is you don't know! The input into this function is not validated. We're making assumptions about the calling code which may or may not be true. The key here is that the concept of "input" doesn't just apply to what you read from they keyboard, a file or the network. It applies to every line of code. Programmers who do not realize this are what I like to call Pavlovian Programmers... Sure, you can teach them a trick (goto is bad!), but they'll never understand the reasoning behind that trick, and they won't be able to apply it to new concept. This is why programmers are jumping on the Event-driven programming bandwagon, despite what an insanely bad idea it is. Basically event-driven programming (the kind that binds anonymous functions as callbacks to events. Yes, javascript et al) is a kind of goto, except for being harder to debug.
Ideally, every function and every constructor would validate its input arguments. (Contracts, anyone?) The stricter you validate input arguments, the less chance there is of winding up in an unpredictable state. Of course I say "ideally", because it is not practical to validate each and every bit of input. A decent compromise would be to validate the input of all constructors that are part of library code. Then again, 99% of your code should be library code. But that's a discussion for another time.
Conclusions
The conclusions of this article are simple:
- Prevent bugs
- Write clear code
I'm not trying to be funny here. The conclusions are the same as what you've already heard a thousand times. I just hope that you now view them in a bit of a different light. I believe we can accomplish the above and create much better code if everybody would just realize a few basic concepts:
- It is vitally important to protect the state at all times.
- Minimize "outside" influences on the state. This includes input from files, the network, other threads that are running, global variables, etc.
- The State in a program is unpredictable all the time. Whenever we read input, whenever a function returns or throws an error, our program is in an unpredictable state. The system should, at all times, move from unpredictable and potentially invalid states to a predictable and valid state. This can be accomplished by validating and sanitizing any input into the program.
I leave you with this quote, which I think I once read somewhere else, but cannot find again, so I will attribute to myself:
Programming is the messy art of constantly bringing a program back to a predictable state after receiving a tiny bit of input.
Wednesday, October 3rd, 2012
(TL;DR: To the solution)
I was mucking about with the Python bindings for libtorrent, and made something like this:
import libtorrent
fname = 'test.torrent'
ses = libtorrent.session()
ses.listen_on(6881, 6891)
info = libtorrent.torrent_info(fname)
h = ses.add_torrent({'ti': info, 'save_path': session_dir})
prev_progress = -1
while (not h.is_seed()):
status = h.status()
progress = int(round(status.progress * 100))
if progress != prev_progress:
print 'Torrenting %s: %i%% done' % (h.name(), progress)
prev_progress = progress
time.sleep(1)
print "Done torrenting %s" % (h.name())
# ... more code
After running it a few times, I noticed the program would not always terminate. You’d immediately suspect a problem in the while loop condition, but in all cases "Done torrenting Foo" would be printed and then the program would hang.
In celebration of one of the rare occasions that I don’t spot a hanging problem in such a simple piece of code right away, I fired up PDB, the Python debugger, which told me:
$ pdb ./tvt
> /home/fboender/Development/tvtgrab/trunk/src/tvt(9)()
-> import sys
(Pdb) cont
Torrenting Example Torrent v1.0: 100% done
Done torrenting Example Torrent v1.0
The program finished and will be restarted
after which it promptly hung. That last line, “The program finished and will be restarted“, that’s PDB telling us execution of the program finished. Yet it still hung.
At this point, I was suspecting threads. Since libtorrent is a C++ program, and as the main loop in my code doesn’t actually really do anything, it seems libtorrent is doing its thing in the background, and not properly shutting down every now and then. (Although it’s more likely I just don’t understand what it’s doing) It’s quite normal for torrent clients to take a while before closing down, especially if there are still peers connected. Most of the time, if I waited long enough, the program would terminate normally. However, sometimes it wouldn’t terminate even after an hour, even if no peers were at any point connected to any torrents (the original code does not always load torrents into a session).
Digging through the documentation, I couldn’t easily find a method of shutting down the session. I did notice the following:
~session()
The destructor of session will notify all trackers that our torrents have been shut down. If some trackers are down, they will time out. All this before the destructor of session returns. So, it’s advised that any kind of interface (such as windows) are closed before destructing the session object. Because it can take a few second for it to finish. The timeout can be set with set_settings().
Seems like libtorrent uses destructors to shut down the session. Adding the following to the end of the code fixed the problem of the script not exiting:
del ses
The del statement in Python calls any destructors (if you’re lucky) on that class. Having nearly zero C++ knowledge, I suspect C++ calls destructors automatically at program exit. Python doesn’t do that though, so we have to call it manually.
Update: Calling the destructor does not definitively solve the problem. I am still experiencing problems with hangs when calling the session destructor. I will investigate further and update when a solution has been found.
Update II: Well, I’ve not been able to solve the problem any other way than upgrading to the latest version of libtorrent. So I guess that’ll have to do.
The text of all posts on this blog, unless specificly mentioned otherwise, are licensed under this license.
